Nome: Silvio César De Lima
Profile:
Cientista de Dados
Especialista IA
Analista de Dados
Email: silviolima07@gmail.com
Fone: (+55)1299646-2527
Habilidades
- Python
- EDA - Análise Exploratória
- Visualização de Dados (Power BI / Tableau)
- Deploy
- WebScrap
- NLP - Natural Langugage Process
- LLM - Large Language Model
- Huggingface
- AWS
- OpenAI / Groq / Gemini
- Machine Learning
- Docker
- Streamlit
- Spaces
- Flask
- CrewAI
About me
Me chamo Silvio César De Lima, pós graduado em Business Intelligence pela universidade de Taubaté e Tecnólogo em Banco de Dados pela FATEC – SJC.
Atuei por mais de 20 anos com suporte e treinamento Unix (Solaris).
Cursando pós graduação em IA aplicada a Industria pela UniSENAI de Santa Catarina.
Experiência com Unix e Linux.
Linguagens:
Python, R e SQL.
Experiência em análise de dados com:
Jupyter Notebook, RStudio e Google Colab.
Visualização de dados com:
Tableau e Power BI.
Deploy de Web apps com:
R / Shiny e Python / Streamlit / Flask.
Algoritmos de Machine Learning com:
R e Python.
Serviços AWS:
EC2, S3, Athena, Sagemaker e outros.
2025
- Novembro de 2025: Residência e Pós graduação em IA Aplicada a Industria pela UniSENAI de Santa Catarina.
- Agosto a Novembro: Residência em dados pela ECOA/PUC-RJ onde me aprofundei no uso do Looker e melhores práticas de visualização de dados.
- Janeiro a Maio: Bootcamp em LLM pela Soulcode. O projeto final foi um assistente virtual para disciplinas ministradas no site da Soulcode.
2024
- Atuei como Bolsista de uma Residência Tecnológica no CPQD. Onde desenvolvi um projeto de Análise de Sentimento Baseada em Aspectos.
Treinamentos:
Bootcamp de Machine Learning - pela PUC Campinas - 08/2023 a 11/2023
Bootcamp de Engenharia de Dados - pela HowEdu - 08/2022 a 10/2022
Bootcamp MultiCloud (AWS | Azure | GCP)- pela TheCloudBootcamp
Certificações AWS:
- Cloud Practitioner
- Solutions Architect Associate
Portfolio de Projetos de Cloud
Serviços de cloud utilizados EC2S3 IAMAnsible Auto ScalingBean Stalk RedshiftTerraform Load BalancerSNS RDSSystem Manager Metabase Power BI
Criar tabelas no Redshift Serverless e gerar um dashboard com Metabase
Ler 5 arquivos csv a partir de um bucket.
Copiar as tabelas dentro do Redshift Serverless.
Gerar um dashboard com Metabase.
Serviços: S3, Iam, Redshift Serverless e Metabase.
Gerar Dados de Vendas e Dashboard no Power BI
Usando a lib Faker criar dados sintéticos de vendas.
Salvar os dados num bucket da AWS.
Gerar um dashboard e atualizar sob demanda ou agendamento.
Serviços: Git Actions, S3, Iam e Power BI.
MVP de um E-commerce
Construção de um MVP de um site de e-commerce.
O Terraform e o Ansible foi usado nesse projeto.
O Magento foi a base de construção do site.
Serviços: EC2, IAM, Terraform, Ansible e Magento.
Execução de comandos em servidores na cloud
Dois servidores precisavam ser atualizados com agentes de segurança.
O Terraform foi configurado para criação da infraestrutura e o System Manager aplicou a atualização em cada instância criada.
Serviços: EC2, IAM, System Manager, SNS e Terraform.
Migração de aplicação on premise para cloud
Uma aplicação, Wiki, rodando localmente foi migrada para execução na AWS.
Foi feito o planejamento do projeto, os recursos foram provisionados e a migração concluida com sucesso.
Serviços: EC2, RDS, VPN, Subnet e Internet Gateway.
Criar contas de usuários via script na AWS
Foram criados 5 grupos para administrar as permissões dos usuários.
Dentro do CloudShell na AWS, foi executado o script bash que cria o usuário no seu respectivo grupo.
Tools: Bash, CloudShell, IAM.
Caged - dados de empregos formais no Brasil
Web scrap de dados do site do Caged usando Python.
Dados são salvos num bucket e posteriormente copiados para um cluster do Redshift.
As tabelas geradas são lidas pelo Metabase, que gera um dashboard apresentando os dados.
Tools: Python, GitHub Action, S3, Redshift e Metabase.
AWS CI/CD - Continous Integration / Continous Delivery
Implementação do CI/CD, usando CodeDeploy, CodeBuild e CodePipeline.
Uma aplicação é recompilada, o código atualizado e a versão nova é levada para um bucket no S3 que hospeda um site estático.
Hands on AWS - Load Balancing
Implementação do serviço de Load Balancing, simulando dois ambientes.
Dois grupos de instâncias distintas, onde uma aplicação HTTP rodando em cada instância do grupo é acessada, de acordo com um filtro implementado na url do DNS do load balancer.
Portfolio de Data Science
CrewAI Linguagens: Python e R Web Scrap Análise Exploratória Treinamento de modelos Deploy de modelos Dashboard MLFlow Pycaret Ngrok PySpark Git Actions Huggingfaces/Spaces

Analisar Ações na B3 com IA
Agentes Inteligentes. Analisar dados históricos de ações na B3. O Prophet faz a previsão de 6 meses e apresenta os gráficos. Um agente do GROQ analisa as previsões.

Que tal Analisar sua Alimentação?
Agentes Inteligentes. Um agente usa um modelo multimodal para descrever uma imagem. Apenas alimentos devem ser detectados. Outro agente no papel de Nutricionista, avalia os alimentos de acordo com observações que o usuário indicar.

RAG
Implementação de um RAG. A base de conhecimento de um modelo é expandida com o upload de novos dados. A partir dai, perguntas são feitas para comprovar o aprendizado.

Chatbot Personas
Assistente Virtual Pode assumir 3 personas diferentes: Instrutor Python, Assistente de Livraria e Cozinheiro

Sugestão de Presentes
Um agente especialista em compras, sugere presentes. Faz 3 sugestões de acordo com critérios definidos pelo usuário.

Descrição de Alimentos em Imagens
Este aplicativo identifica alimentos numa imagem e faz uma descrição. Um agente do CrewAI usando o modelo llava faz a descrição e outro agente usando llama, no papel de Nutricionista, avalia os alimentos.

Revisão de Perfil no Linkedin
Este aplicativo faz uma revisão e recomendações do perfil do usuário no Linkedin. Um agente do CrewAI no papel de Especialista em Recrutamento analisa as seções e indica melhorias.

Gerador de Gráficos
Este aplicativo faz uma recomendação de gráficos a partir de um conjunto de dados fornecidos. Um agente do CrewAI no papel de Especialista em Visualização análisa os dados, explica as colunas e propõe gráficos para entender o contexto a partir dos dados.

Próximo Destino
Este aplicativo faz uma recomendação de pontos turisticos em 5 Estados do Brasil. Um agente do CrewAI no papel de Guia Turisticos faz uma pesquisa baseada nos critérios definidos e recomenda lugares para visitar.

Revisão de Currículo
Este aplicativo faz a leitura de um curriculo em pdf. Um agente do CrewAI no papel de Recrutador faz a leitura e recomenda melhorias tais como incluir palavras_chaves..

Análise de Viagens de Ônibus em 2019
Identificar insights a partir do serviço prestado. Foram lidos 6GB de dados usando pyspark, foram feitos agrupamentos criando assim diferentes conjuntos para análise. Foram gerados diversos gráficos e por um modelo usando Prophet, prevendo a quantidade de viagens para a cidade de São Paulo.

Fake Data
Criação de dados para testes de modelos e análises. Existem templates de dados prontos, tais como nomes, endereços e sexo. Novos dados podem ser criados de acordo com a necessidade e objetivo.
Colab, MLFlow, Ngrok e Pycaret
Exemplo de integração de ferramentas para análise de Churn.
Colab - ambiente de desenvolvimento.
MLFlow - salvar os artefatos (parametros, graficos, etc...) gerados.
Ngrok - compartilhar o desenvolvimento do app.
Pycaret - tratar, treinar os dados e avaliar os modelos.
Github Action: Atualizando um dashboard
Veja-> Dashboard Vagas em Data Science
Atualização e publicação de dashboard criado com Datapane.
A execução dos passos é administrada pelo Github Action.
Que permite gerenciar o ambiente de execução, a sequência dos passos e também acessar Tokens/Keys como variáveis de ambiente, mantidas criptografadas em Github/Settings/secrets.
Github: https://github.com/silviolima07/datapane-vagas
Integrando: PDI, S3 e Power BI
Levando dados via Pentaho PDI até o serviço de repositório AWS, Bucket S3.
Buscando os dados no S3 através de scripts Python no Power BI.
Chatbot B3
Chatbot que traz a cotação de 3 ações.
Faz a previsão usando a lib Prophet.
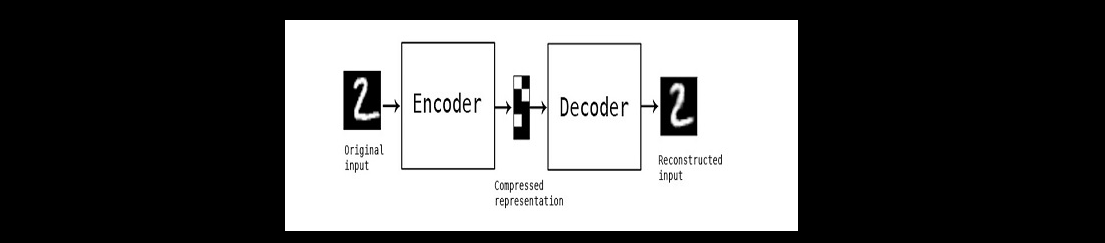
AUTOENCODER
- Detecção de Anomalias / Fraude
- Remoção de Ruido / Redução de Dimensão
A arquitetura do autoencoder se baseia no aprendizado de caracteristicas de entrada, que devem estar presentes na saida.

Previsão de Preço
Projeto que iniciou com a coleta de dados, via scrap em sites de venda de apartamentos.
Seguido pelo tratamento dos dados, treinamento do modelo e deploy na nuvem.
Veja em Artigos e Raio-X

Kaggle & Colab
Análise exploratória, treinamento e avaliação de modelos.
- Comparecimento as Consultas no Sus
- Classificação da Pressão Sanguinea
- Segmentação de Clientes

Previsão da Ação Petr4
Exemplo de aplicação do algoritmo Arima numa série temporal.

Tableau Public
Diversos dashboards construidos com dados públicos.

Controle de Peso
Modelo configurado para descoberta dos itens que respeitem critérios.
O peso total <= 10kg.
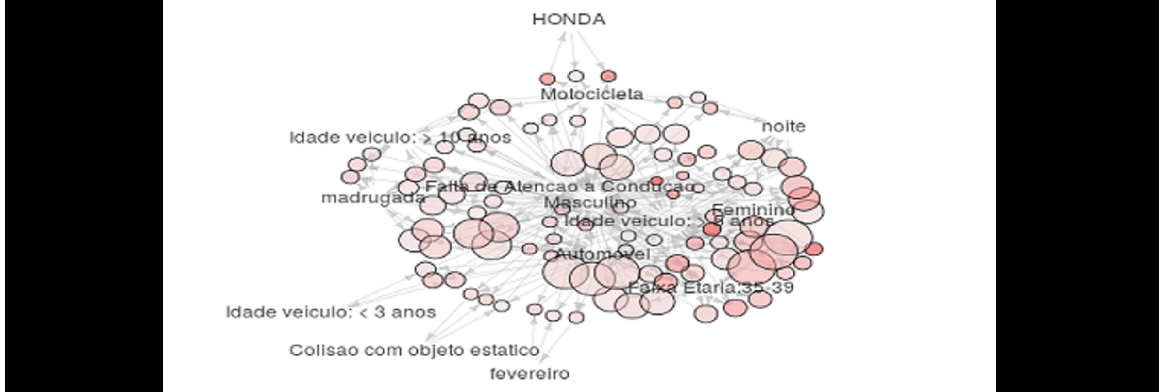
Análise de Acidentes de Transito
Descoberta dos elementos que compõem um acidente de trânsito.

Rpubs
Estudos de aplicação de R para criação de gráficos.
Rpbus repositório público.

R - Modelo Titanic
Modelo construido usando R.
Raio-X
Detalhes - Frameworks - Github
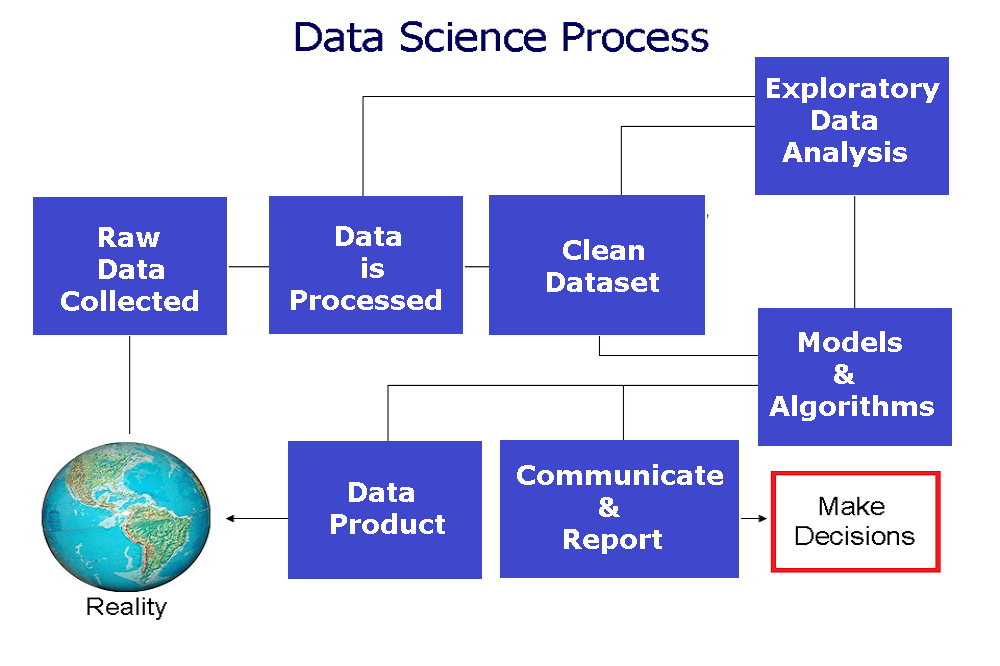
Etapas do Processo
Definição
A partir do entendimento pleno de um problema enfrentado no dia-dia pelo cliente, definir as possíveis fontes de dados que compõem a solução.
Uma vez coletados, iniciam-se as etapas de tratamentos e limpeza dos dados, bem como a análise exploratória.
De acordo com o problema, algoritmos são treinados e avaliados até atingir um valor de precisão acordado. Todas etapas, podem se repetir, dependendo das decisões que serão tomadas.
Com o modelo concluído, temos a entrega, onde um relatório de testes e documentação são entregues. Podendo a solução ser acessada por exemplo na forma de uma aplicação web na nuvem.
Web Scrap
Coleta de Dados
Empresas precisam tomar decisões diariamente, a partir de dados históricos acumulados, essa tomada de decisão pode ter maior probabilidade de acerto, quando suportada por dados.
Porém, nem sempre dados internos bastam e outras fontes precisam ser consultadas e mais dados incluidos.
Web Scrap, permite exatamente essa operação. A partir de bibliotecas Python ou R, páginas da internet podem ser lidas e as informações desejadas serem extraidas e assim gerar uma base de dados nova.
No modelo que faz Previsão do Preço Venda de Apartamento, fiz o scrap em 200 páginas e extrai 4000 anúncios.
Código:
Github-Regression_Apartment

Deploy
Deploy do modelo
A conclusão de um projeto de machine learning, pode se constituir da entrega dos relatórios de teste, a documentaçao gerada e de uma aplicação web, onde o cliente possa testar e avaliar a eficácia da solução.
A empresa pode verificar junto do pessoal de TI interno, a melhor forma de tornar a solução disponível aos interessados.
Em meus trabalhos com R usei a infraestrutura da RShinyApps para hospedar minhas aplicações usando a biblioteca Shiny.
Para aplicações Python, construidas usando as bibliotecas Streamlit e Flask, fiz a hospedagem no Heroku.
Basta acessar a url e utilizar.